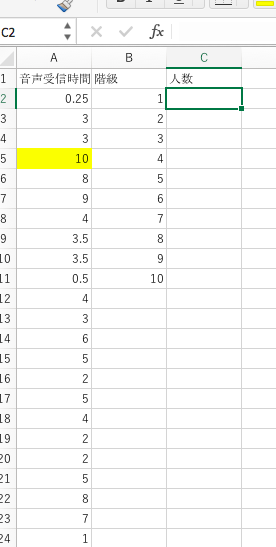
ここでは、社会言語学講義で集めた言語行動に関するデータを例に解説します。ある日の講義で「昨日、音声を使って何時間情報を受信しましたか。音声を使って情報を発信した時間は何時間ですか。文字を使って情報を受信した時間は何時間ですか。……」といった質問をしました。そこで集まった音声を受信した時間を示したものが、以下の図にあるデータです。
結構ばらつきがあるのですが、10時間音声で情報を受信した人がおり、「インターネットの時代だからテレビやラジオを受信する時間が短くなったと思っていたんだけど意外だな」と感じました。しかし、10時間が例外的であることを客観的に示すにはデータの分布を示す必要があります。そこでfrequencyという関数を使ってデータの分布を調べることにしました。
まず、データの分布を数える間隔を設定します。上の図で「階級」と書いたセルの下に「1, 2, 3, 4, 5, ..., 10」とあります。これがその間隔です。これで、0時間から1時間の間と答えた人数が何人か、1時間から2時間の間と答えた人数が何人かを調べようというわけです。
次に「人数」の下のセルを選択します。一つのセルだけでなく隣にある「階級」で文字が入っているのと同じ行数のセルを選択します。
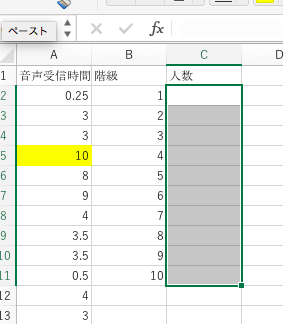
次に上の図のようにセルを選択したまま、関数を記入する窓に、
=frequency(データ配列, 区間配列)
を記入します。
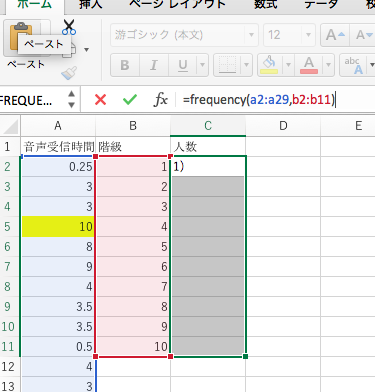
「データ配列」にはデータが入っているセルの範囲を記入します。上の図では、「a2:a29」です。「区間配列」には人数を数える間隔が指定されているセルの範囲を記入します。上の図では、「b2:b11」です。
通常はここでリターンキーを押せばよいのですが、それではダメです。必ず、ShiftキーとControlキーを押しながらリターンキーを押してください。
そうすると、以下の図のように区間ごとの人数が示されます。
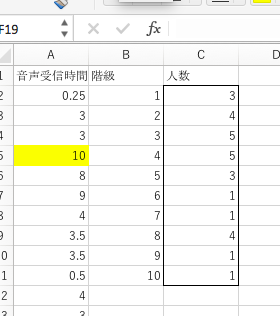
上の図では、音声による情報の受信が0時間から1時間だった人が3名、1時間から2時間だった人が4名、2時間から3時間だった人が5名……であったことがわかります。これを折れ線グラフで示したものが下の図です。
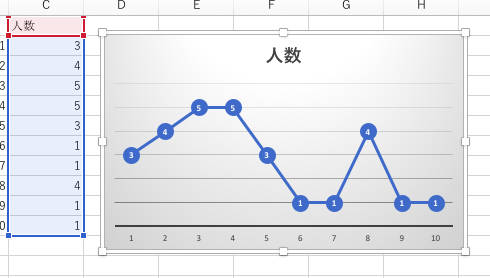
2時間から4時間のところに一つのピークがあり、7時間から8時間のところにもう一つのピークがあることがわかります。そして、10時間というのが、ピークから外れているという点で、典型からずれた数値であることがわかります。
     |