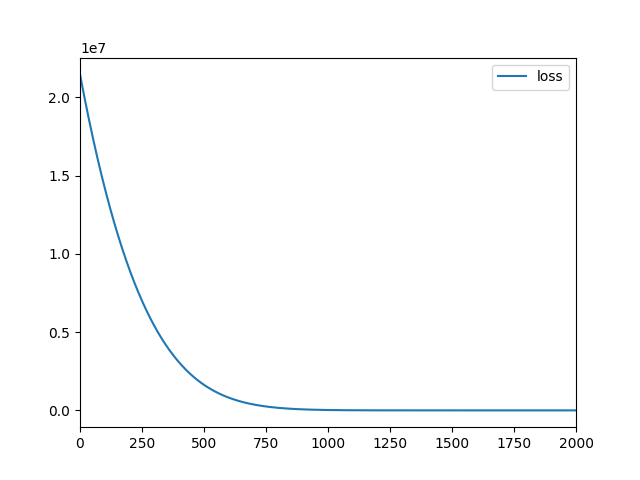
| ex1-1.log |
|---|
| ex1-1.png |
 |
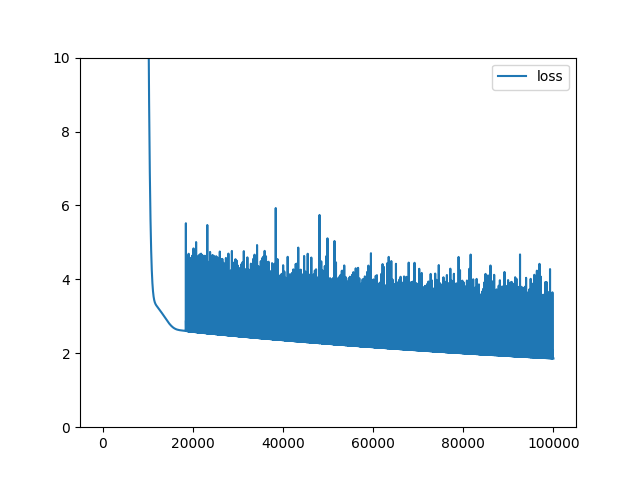
| ex1-2.log |
|---|
| ex1-2a.png |
 |
| ex1-2b.png |
 |
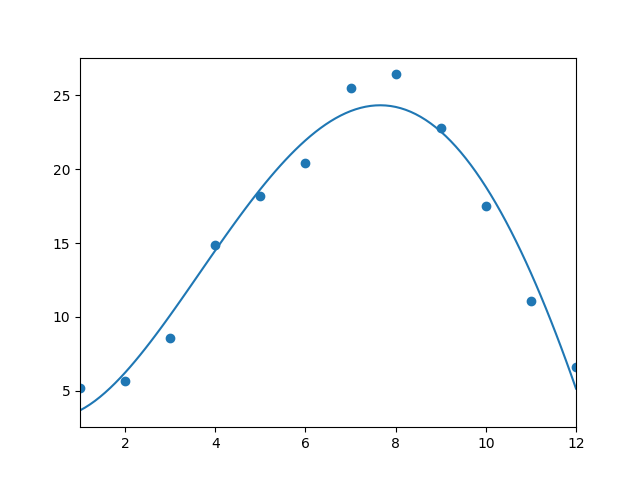
| ex1-2.png |
 |
技術資料& 課題 written by いずみ♡ @ 立命館大学 理工学部 電子情報工学科
研究室にまあまあの性能の GPU マシンを用意している。 自PCから接続して使用することができる。 ぜひ活用されたし。
ついでに、NVIDIA GPU を搭載した Windows 10 マシンで TensorFlow (with GPU) を走らせる方法も記載しておく。
VPN接続、電源オン、ログインなどの詳細は manaba+R の卒業研究のコースにて確認するか、泉に尋ねること。(外部から見える場所にはおけないので)
TensorFlow はバージョン等によって必要な実行環境が異なる。 環境を切り替えるようにしていないとうまく動かない。 そのための venv というツールがあり、 これを利用してバージョン毎の環境を構築する。
| for TensorFlow 1.14 (CPU mode) |
|---|
# sudo apt install python3-dev python3-pip python3-venv python3-tk # 管理者のみ # python3 で python3.6 が実行される python3 -V python3 -m venv --system-site-packages ~/venv-tf1 source ~/venv-tf1/bin/activate python3 -m pip install psutil python3 -m pip install numpy==1.16.4 python3 -m pip install pandas python3 -m pip install matplotlib python3 -m pip install tensorflow==1.14 : deactivate |
| for TensorFlow 2.6 |
|---|
# sudo apt install lsb-core # sudo apt install python3.8 python3.8-dev python3.8-venv python3-tk # 管理者のみ # 必ず python3.8 を使うこと。python, python3 はバージョンが違う。 python3.8 -V python3.8 -m venv --system-site-packages ~/venv-tf2 source ~/venv-tf2/bin/activate python3.8 -m pip install --upgrade pip python3.8 -m pip install --upgrade psutil python3.8 -m pip install numpy==1.19.5 python3.8 -m pip install scipy==1.10.1 python3.8 -m pip install pandas==1.4.4 python3.8 -m pip install matplotlib==3.6.3 python3.8 -m pip install protobuf==3.20.3 python3.8 -m pip install keras==2.6 python3.8 -m pip install tensorflow==2.6 : : deactivate |
source ~/venv-tf2/bin/activate # vent-tf2 の部分に venv で作った環境の保存場所が入る |
deactivate # そのままログアウトするなら deactivate はしなくても大丈夫 |
『 TensorFlow と Keras で 動かしながら学ぶ ディープラーニングの仕組み 』 (中井悦司, マイナビ出版, 2019)の サンプルコード を実行する例を示す。 第1章の最初のサンプルコード " 1. Least squares method with low-level API " は TensorFlow 1.*系の例、 ふたつめのサンプルコード " 2. Least squares method with Keras " は TensorFlow 2.*系の例、のようである。
これらに次の変更を加える。
変更・追加したソースコードは以下のとおり。この3つをダウンロードして適当なデ ィレクトリに置いておく。
| ex1-1.py |
|---|
| ex1-2.py |
|---|
| specrep.py |
|---|
実行の例を以下に示す。
cd ~/colab_tfbook/Chapter01/ # ex1-1.py, specrep.py を置いたディレクトリの例 source ~/venv-tf1/bin/activate # 1.* 用の環境にする python3 ex1-1.py # 結果を画面に出力する場合 python3 ex1-1.py > ex1-1.log # 結果をログファイルに保存する場合 deactivate # 1.* 用の環境を終了 |
cd ~/colab_tfbook/Chapter01/ # ex1-2.py, specrep.py を置いたディレクトリの例 source ~/venv-tf2/bin/activate # 2.* 用の環境にする python3.8 ex1-2.py # 結果を画面に出力する場合 python3.8 ex1-2.py > ex1-2.log # 結果をログファイルに保存する場合 deactivate # 2.* 用の環境を終了 |
実行結果の例を以下に示す。
| ex1-1.log |
|---|
| ex1-1.png |
|
| ex1-2.log |
|---|
| ex1-2a.png |
|
| ex1-2b.png |
|
| ex1-2.png |
|
『 TensorFlow と Keras で 動かしながら学ぶ ディープラーニングの仕組み 』 (中井悦司, マイナビ出版, 2019)の サンプルコード について、 2章以降も含めて いずみ研の環境で実行するように修正したサンプルコード他を colab_tfbook_rizm.tgz にまとめた。
設定メモ: /usr/local/cuda/bin に PATH を通す。 /usr/local/cuda/lib64 に LD_LIBRARY_PATH を通す。
このうち、次の3つの学習について、学習にかかる計算時間を計測する。 model.fit(), model.fit_generator(), または model.train_on_batch() のループの 直前の開始時刻と直後の終了時刻を time.perf_counter() で計測し算出する。
それぞれのレイヤ構成、学習の設定は次の通りである
| レイヤ構成 |
|---|
Input: 28*28 pixels, 1plane(Gray) Conv2D: 5*5 kernel, 32filters, ReLU MaxPool: 1/2*1/2 Conv2D: 5*5 kernel, 64filters, ReLU MaxPool: 1/2*1/2 FullCon: 1024 nodes, ReLU Dropout: FullCon: 10 nodes, Softmax Output: 10 categories 3,274,634 params in total |
| 学習の設定 |
60000 train data * 10 epochs batchsize 128, ADAM optimizer |
| レイヤ構成 |
|---|
Input: 32*32 pixels, 3plane(RGB) Conv2D: 3*3 kernel, 32filters, ReLU Conv2D: 3*3 kernel, 32filters, ReLU MaxPool: 1/2*1/2 Dropout: Conv2D: 3*3 kernel, 64filters, ReLU Conv2D: 3*3 kernel, 64filters, ReLU MaxPool: 1/2*1/2 Dropout: FullCon: 512 nodes, ReLU Dropout: FullCon: 10 nodes, Softmax Output: 10 categories 2,168,362 params in total |
| 学習の設定 |
50000 train data * 20 epochs データ拡張あり, batchsize 64, ADAM optimizer |
| レイヤ構成 |
|---|
生成器 (614,145 params in total) Input: 64 values FullCon: 7*7 pixels, 128 planes, LeakyReLU Conv2D: 5*5 kernel, 64 filters, 2*2 expand, LeakyReLU Conv2D: 5*5 kernel, 1 filter, 2*2 expand, LeakyReLU Output: 28*28 pixels, 1plane(Gray) 識別器 (212,865 params in total) Input: 28*28 pixels, 1plane(Gray) Conv2D: 5*5 kernel, 64 filters, 1/2*1/2 shrink, LeakyReLU Conv2D: 5*5 kernel, 128 filters, 1/2*1/2 shrink, LeakyReLU Dropout: FullCon: 1 node, Sigmoid Output: binary |
| 学習の設定 |
以下を 40,000 steps 識別器のバッチ学習 batch_size = MNIST画像32枚 + 生成画像32枚, ADAM optimizer 生成器のバッチ学習 batch_size = 乱数32セット, ADAM optimizer |
実験に使用した計算機は次の5台である。 このうち(1)(2)については、GPU使用/不使用(CPUのみ)の二通りで実験した
| 仕様 |
|---|
CPU: Intel Core i9-9900X (10C20T, 3.50GHz, 20MB cache) + 64GB mem OS: Ubuntu 18.04.5 NVIDIA GeForce RTX2080 Ti (11GB) NVIDIA Driver 470.57.02, CUDA 11.4, CUDNN 8.2.4 Python 3.8.0, TensorFlow 2.6.0 |
| 仕様 |
|---|
CPU: Intel Core i7-10875H (8C16T, 2.30GHz, 16MB cache) + 32GB mem OS: Windows 10 Pro 64bit 日本語 build 19042.1237 GPU: NVIDIA Quadro T1000 Max-Q (4GB GDRR5) NVIDIA Driver 471.41, CUDA 11.4, CUDNN 8.2.4 Python 3.9.6, TensorFlow 2.6.0 |
| 仕様 |
|---|
Intel Core i7-10700 CPU (8C16T, 2.90GHz, 16MB cache) + 32GB mem OS: Ubuntu 18.04.5 Python 3.8.0, TensorFlow 2.6.0 |
| 仕様 |
|---|
Intel Xeon E5-2667 v4 (8C16T, 3.20GHz, 25MB cache) + 32GB mem OS: Ubuntu 20.04.3 Python 3.8.10, TensorFlow 2.6.0 |
| 仕様 |
|---|
CPU: Intel Core i5-4570 (4C, 3.20GHz, 6MB cache) + 16GB mem OS: Ubuntu 18.04.6 Python 3.8.0, TensorFlow 2.6.0 |
| 仕様 |
|---|
CPU: Intel Core i9-10940X (14C/28T, 3.30GHz, 19.25MB cache) + 16GB mem NVIDIA RTX A5000 (24GB) OS: Ubuntu 20.04.3 NVIDIA Driver 470.74, CUDA 11.3.109, CUDNN 8.8.0 Python 3.8.10, TensorFlow 2.6.0 |
各学習に各計算機での計算時間を次の表にまとめる。
| [ex5-1] MNIST | [ex5-5] CIFAR-10 | [ex5-7] DCGAN | [ex2-1] 回帰 | |
|---|---|---|---|---|
| (1) i9-9 + RTX2080 | 17.6 | 410.4 | 1361.9 | 6.2 |
| (2) mobile i7-10 + T1000 | 53.4 | 487.6 | 2261.6 | 14.7 |
| (1') i9-9 | 131.4 | 635.8 | 1881.9 | 3.4 |
| (6) i9-10 + RTX A5000 | 35.2 | 648.4 | 2957.8 | 20.1 |
| (3) i7-10 | 193.0 | 775.9 | 1788.5 | 3.2 |
| (6') i9-10 | 122.9 | 802.4 | 3491.3 | 10.4 |
| (4) Xeon E5 | 205.2 | 906.8 | 3044.7 | 7.8 |
| (2') mobile i7-10 | 366.8 | 1875.5 | 3872.1 | 4.1 |
| (5) i5-4 | 478.6 | 1810.0 | 4286.3 | 5.2 |
CPUでの計算では、概ね新しい世代のもの高性能なものが速い(1'>3>4>2'>5)、ことが見て取れる。 [ex5-1] [ex5-5] の典型的な畳み込みニューラルネットワークの学習では、 GPUの性能が引き出され RTX2080, mobile T1000 ともに高性能プロセッサを凌駕している。 [ex5-1] と比べて [ex5-5] の性能向上が控えめなのは、 バッチごとにデータ拡張の処理が入り、それがGPUの効率的処理を妨げているのかも知れない。 [ex5-7] では mobile T1000 GPU が i9-9, i7-10 CPU よりも遅くなっている。 DCGANではバッチごとに学習対象の入れ替え(識別器⇔生成器)られ、 CPU の介入が必要かつ GPU の一様連続処理が妨げられることで、 GPU が活用しきれない状況になっていると思われる。 なお、参考までに、単純な2変数のロジスティック回帰 [ex2-1] では、 GPU を使用するとむしろ遅くなる。 計算が逐次的な場合にはGPUの並列性が活かされず、CPUが優位である。 (6) RTX A5000 は期待ほど性能が出ていない。 DeepLearningのライブラリが整数演算器向けに最適化されており、 (1) RTX 2080 Ti や (2) T1000 で性能が出やすいためと思われる。 (6') i9-10 が (1') i9-9 を下回っているのは、搭載メモリの差(16GB v.s. 64GB)と思われる。 また (6),(6') は2年遅れで実験しており、 無理なバージョンダウンによる不整合のために遅くなっている可能性もある。
以下は他のやり方など調査中、まとめ中のメモ
| docker インストールから動作確認 |
|---|
sudo apt update
sudo apt install apt-transport-https
sudo apt install ca-certificates
sudo apt install curl
sudo apt install gnupg-agent
sudo apt install software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo apt-key fingerprint 0EBFCD88
#ここ↓arch と release を確認すること
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo vi /etc/systemd/system/docker.service.d/http-proxy.conf
sudo systemctl daemon-reload
sudo systemctl restart docker
systemctl show --property=Environment docker
sudo usermod -aG docker ${USER}
sudo docker run --rm hello-world
|
| docker container 準備 |
|---|
docker images ---------------------------------------------------------------- # ubuntu:18.04, python3.6, numpy==1.16.4, tensorflow==1.14 sudo docker run \ --name con-tf1 \ -p 10022:22 \ -v /var/docker:/var/docker \ -it ubuntu:18.04 /bin/bash adduser --uid 1000 --home /home/t-izumi t-izumi apt update apt install net-tools iputils-ping vim ssh xserver-xorg x11-apps pciutils vi /etc/ssh/sshd_config # allow X11 forwarding #export DISPLAY=192.168.11.80:0.0 service ssh restart systemctl enable ssh apt install software-properties-common add-apt-repository ppa:deadsnakes/ppa apt install python3.6 python3.6-dev python3-pip python3 -m pip install numpy==1.16.4 python3 -m pip install tensorflow==1.14 python3 -m pip install matplotlib python3 -m pip install pandas python3 -m pip install psutil ---------------------------------------------------------------- |
| docker container 準備 |
|---|
docker images ---------------------------------------------------------------- # ubuntu:20.04, python3.8, tensorflow==2.6 sudo docker run \ --name con-tf2 \ -p 10022:22 \ -v /var/docker:/var/docker \ -it ubuntu:20.04 /bin/bash adduser --uid 1000 --home /home/t-izumi t-izumi apt update apt install net-tools iputils-ping vim ssh xserver-xorg x11-apps pciutils vi /etc/ssh/sshd_config # allow X11 forwarding #export DISPLAY=192.168.11.80:0.0 service ssh restart apt install software-properties-common add-apt-repository ppa:deadsnakes/ppa apt install python3.8 python3.8-dev python3-pip python3 -m pip install numpy python3 -m pip install tensorflow==2.6 python3 -m pip install matplotlib python3 -m pip install pandas python3 -m pip install psutil ---------------------------------------------------------------- |
| docker 基本動作 memo |
|---|
docker ps -a
cid=ContainerID
#images
docker pull
docker images
docker rmi
#remove
docker stop $cid
docker rm $cid
#continue session
docker start $cid
docker restart $cid
docker attach $cid
|
penv というツール python の複数バージョンを管理できるらしい
docker + GPU は面倒 : 当初 docker でできるだろうと考えて試行錯誤したのだが、 でききなくはないが面倒、という結論に達した。 Windows10 + WSL2 + Docker で Ubuntu18.04+Python3.6 や Ubuntu20.04+Python3.8 の仮想環境を 切り替えて使うことはできたがGPU (--gpus all) が使えない。 WSL2 で GPU を使うには Windows 10 のバージョンアップが必要で、 それは Insider Preview でいわゆる Win11 相当にしないといけないらしい。
Python のインストール方法に注意 : それなら Windows native で環境を構築するしかないかと試行錯誤したが、 インストールできたようでいざ tensorflow を実行すると cuda ライブラリが読み込めずに GPU なしでの計算になってしまう。 cudart64_110.dll はそこにあるし PATH も通しているのに! いろいろ調べたところ Python を Microsoft Store からインストールしたらダメで Python 公式サイトからダウンロードしてインストールしたら大丈夫とのこと。 そうしてみたら動きました… 言わせてください… 「なんでやねん!」
以下、動作確認できた、インストールのポイント、バージョン、など