
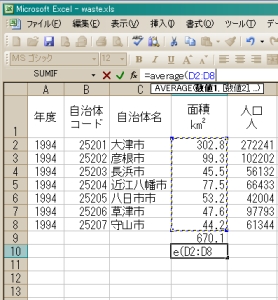

(1)平均値
統計処理の基本は,標本集団の「平均と分散」である.この場合の「平均」とは,一般的には「算術平均」,すなわち,「各標本データの総和をサンプル数で除した結果」.さて,さっきからいろいろと計算を試し始めているマイデータ(ふるさと都道府県の自治体のデータ)の中で,「面積」データの算術平均を求めるにはどうすればいいだろう.さっきみたいに「セルごと足して足して」をして合計を計算して標本数(自治体数)で割る?,それはちょっとめんどう.
そこで登場するのが「関数」という道具である.早速,算術平均を一瞬で計算してくれる「average」という関数を使ってみよう.さっきと同じように,「面積」の列(D列)の下の方の適当な空白セルをクリックしてアクティブ(入力可能状態)にする.まず半角文字で「=」を入れてから「average」という文字(半角アルファベット)を打ちこみ,さらに「(」,半角カッコ開ける印を打った後で「算術平均を求めるデータの入ったセル」を一括選択する.「面積」データなので,D列2行目のセル(D2)からD列でデータの入ってる最後のセル(D?)までを一気にドラッグすればOK.
|
|
|
ドラッグするにはセル数が多くて大変な場合は,いったんD列2行目のセル(D2)をクリックした後,「shift」キーを押しながらD列でデータの入ってる最後のセル(D?)をクリックすると一括選択完了.この「shift」キーを使った一括選択方法は,マイデータを作るときに複数行を一気に消したときと同じ.最後に「)」,半角カッコ閉じる印を打って「Enter」キーを押すと「算術平均」計算結果が現れる.
同じ手順で,「average」の代わりに「sum」という関すを使えばデータの総和(さっきまで足して足してで苦労して計算してた),「counta」という関数を使えばデータの個数(正確には,空白でないセルの個数)が出てくる.「stdev」はおなじみ標準偏差,「max」は最大値,「min」は最小値.いずれも「関数名」の後の「()」半角カッコの中に対象となるデータの範囲を「セルごとまとめてドラッグして一括選択」することで,どんなに膨大なデータが相手でも一瞬のうちに計算結果が出てくる.じゃあさっきまでの「足して足して・・・」の面倒な作業はいったい何だったんだと言わないように.物事を知るには手順というものが・・・.
(2)割り算で地域の指標をつくる
ここでは,再び基本的な「足して引いて掛けて割って」に戻ろう.といっても,もう「面倒な作業」ではない(はず).改めて,市制自治体ごとの社会経済特性データの意味を考えてみる.例えば,「面積」と「人口」のデータを見ているうちに「人口密度」という指標が思い浮かんでくる(?).さすがは,環境都市系.人口密度の高いところは都市的土地利用の割合が高いから収入も商店の売り上げも高いとちがうかなあと考えるようになってくる(?).物がたくさん売れるということは,ごみもたくさん出るのかなというところまで考えがおよんでくる(?).そうは言っても,人口が多い自治体の総収入金額が多いのは当たり前なような気もするし,人がいっぱい住んでいればごみも多いというのも特にめずらしくはなさそう・・・そうか,わかった.元のデータを人口1人あたりの比率として計算してみたら面白いかもしれない(と思うようになれば,一人前の環境都市系).
ということで,ここではひたすら「割り算」マニアになりきる.名付けて,「割って割って割って割って延々と割り続けて考えてみよう,地域の社会経済指標」大作戦.これまでのように「縦方向にデータを組み合わせて(同じ列にあるデータを使って)計算する」のではなく,「横方向にデータを組み合わせて(同じ行にあるデータを使って)計算する」というところに注目.すなわち,標本ごとの(自治体ごとの)元データを組み合わせて計算することにより,標本ごとの(自治体ごとの)新たな変数をつくるということ.ここで言う「新たな変数」とは様々な地域の社会経済特性を表す地域指標である.
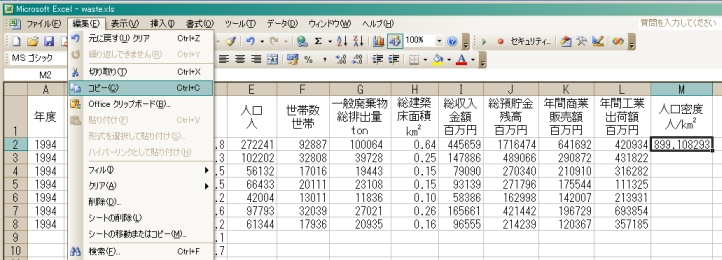
まずは,「人口密度」.マイデータ(ふるさと都道府県の自治体のデータ)の中の2行目(最初の自治体)について,右端の空白セル(住所はM列2行)に人口密度の計算結果を表示させてみよう.例によって,始めに「=」を入れた後で「セルごと」割り算だから,「人口(E列2行)」/「面積(D列2行)」そのまんまセルをクリックしながら入力(=E2/D2)してEnterキーを押すと,出ました人口密度.単位はもちろん「人/km2」だから,1行目に単位を付け足しておこう.さて3行目(次の自治体データ)以降も同じ手順で人口密度を計算していこう.といっても,もう「面倒な作業がない」というのは約束通り.「今度は割って割ってを何十回も繰り返すの?」と思った人も大丈夫.便利な「コピー&ペースト」を身につけよう.

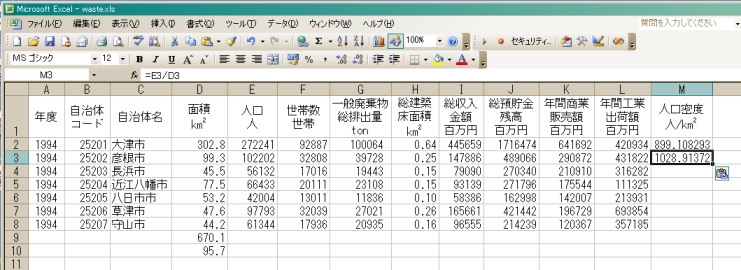
既にワードを使った文章編集でおなじみの(はずの)「コピー&ペースト」だが,Excelの中の「コピー&ペースト」はさらに強力.早速だが,いま人口密度計算式を入力したばかりの2行目右端のセル(M列2行)をクリックしてアクティブにしよう.そのままメニューバーの「編集」から「コピー」を選ぶ.そして,同じM列の4行目の空白セル(M列3行)をクリックしてアクティブにした後で,メニューバーの「編集」から「貼り付け」を選ぶ.3行目の人口密度が計算できている.しかも,3行目の計算結果の数字がコピーされたのではなく,ちゃんと3行目の人口密度計算式(=E3/D3)が「セル内容表示」に出ている.Excelでは,中身が計算式のセルをコピー&ペーストすると,計算結果の数値ではなく「計算式」そのものが「計算対象セルの相対的な位置関係」を保ったままコピーされるということ.とにかく,言葉で理解するよりも身体で覚えよう.何が起きているのかが解るまでひたすら「セルごとコピー&ペースト」を繰り返してみよう.
 |
 |
 |
|
 |
(3)連続一括計算
「コピー&ペースト」を理解したとは言え,何十行にもわたって(全国データだと657行!)コピー&ペーストするのは結局「面倒な作業」じゃないか?.大丈夫,約束通りイージーな道はいつでも開かれている.コンピュータというものは基本的に面倒くさがり屋が発展させてきたものであり,「どうすればもっと楽ができるか?」という気持ちを忘れなければ,情報処理能力はどんどん磨かれていく(勉強しなくていいということではない,誤解しないように).「えーっ,ひとつひとつコピー&ペーストして地道に作業してしまいました.どうして,いつも便利なやり方を後になって教えるのですか?.」と言っている人の努力も無駄にはならない.人生は長い.3行目以降の人口密度計算を瞬時に完成させる方法は,以下の通り.始めに人口密度計算式を入力したセル(M列2行)をクリックしてアクティブにした後で,「shift」キーを押しながら同じ列(M列)の一番下のセル(データの入っている最終行のセル)をクリックする.これで,人口密度の計算結果を出したいセル全部を一括選択したことになり,一括選択範囲の先頭に計算式が入力済みの状態となっている.ここでおもむろに, キーボード左下にある「Ctrl」キー(コントロール・キーと呼ぶ)を押しながら「D」を押す.
何が起きたか解ったかな?.人口密度の計算結果が表示されているセルをひとつひとつクリックして,「セル内容表示」を確かめながら何が起きたかしっかり理解しよう.今使った方法は,「下への連続コピー」.一括選択された複数セルを対象に,いちばん上の行のセル内容を縦方向下に向かって連続一括コピーするという「表計算ソフト独特のセル連続コピー」と覚えておこう.「Ctrl」キーといっしょに押した「D」は「down」の「D」.世の中,縦があれば横もある.一括選択された複数セルを対象に,「いちばん左の列」のセル内容を「横方向右に向かって」連続一括コピーするというコンビネーションも用意されている.面積の合計や平均値を計算したセルを使って確かめてみよう.画面の下の方にある既に計算式入力済みのセル(面積の合計などを計算したところ)をクリックした後で,「shift」キーを押しながら同じ行の右端セル(さっき計算したばかりの人口密度列の下の方)をクリック.どきどきしながら(というほどでもないが),「Ctrl」キーを押しながら「R」を押す.もはや説明不要.もちろん,「R」は「right」の「R」.
いろいろやっているうちに, 「########」のような「桁がオーバーフローして数値が表示されないセル」が出てくるかもしれない.そのときは,「足したり引いたり掛けたり割ったり」で習ったように,「セルの横幅(列の幅)」を広げてやるとOK.それから,小数点以下の桁数がやったら多くなってうっとうしいときは,「書式」メニューの「セル」を選び,「表示形式」を「数値」として「小数点以下の桁数」に適当な数字を入れればOK.実は,小数点以下の桁数をコントロールするための「らくらくボタン操作」が画面上方に並んだ印の中に隠れている.たまには自分で探してみよう.
(4)データの並べ替え
ついでに,「データの並べ替え」というのも知っておこう.例えば,いま見ているマイデータの中で「いちばん面積の広い自治体」をどうやって探すか?.「目で見たらわかる?」・・・確かに,4つ5つからせいぜい20個ぐらいのデータ見ていちばん大きい数値を探すのにコンピュータは不要.でも,日本全国657市制自治体のデータから各変数(社会経済特性)の最大や最小を目で見て探す?.そうそう,最大見つけるなら「max」,最小見つけるなら「min」という関数を使えば簡単.じゃあ,君の故郷の街の「1人1日あたりのごみ排出量」が国内の都市で何番目に多いかを知るには?.
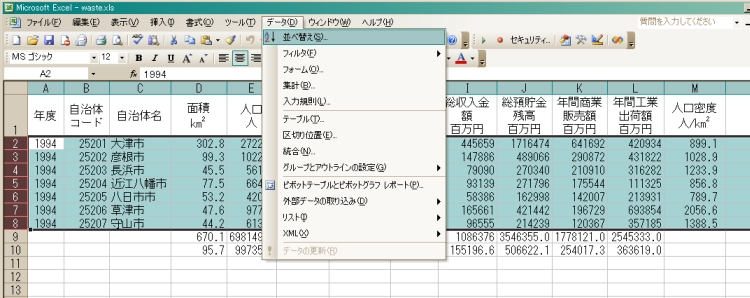
そこで登場するのが,メニューバー「データ」のところの「並べ替え」.マイデータの入っているワークシート左端の「行番号」クリックで自治体データの入っている行を一括選択しよう.まず,2行目(いちばん始めの自治体データ行)の行番号(2)をクリックした後で, 「shift」キーを押しながら最後の行(いちばん下の自治体データ行,その下の合計や平均値を計算した行は入れない)の行番号をクリック.このような,「データ並べ替え対象を一括選択」した状態で,メニューバー「データ」のところの「並べ替え」を選ぶ.
 |
||
 |
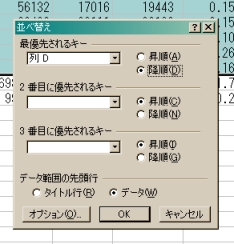
「並べ替え」という小窓が開く.並べ替え小窓の下の方にある「先頭行」のところで「データ」が選択されていることを確認し,選択されていない場合にはクリックして選択する.上から順に,「最優先されるキー」,「2番目に優先されるキー」,「3番目に優先されるキー」,とあるが,最優先されるキーのところを「列D」とする.そのすぐ右に「昇順」と「降順」を選ぶようになっているが,「降順」を選ぼう.「2番目」と「3番目」はとりあえず無視.これで「面積(D列の数値)の大きいデータ(自治体)から順に並べ替える」準備が整った,最後に「OK」ボタンを押す. | |
 |
 |
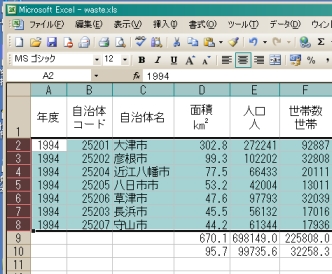 |
何が起きたか解ったかな?.面積の数値のところだけが大きい順に動いたのではなく,面積の数値の大きさの順番に従って,自治体名も他の変数も連動して「行」ごと順番が並べ替えられたところに注目しよう.これで,データ数が何百でも何千でも何万でも「君の故郷○○市の1人あたりの預貯金残高は,日本の市制自治体の中で何番目に多い?」という問いに瞬時に答えられるようになった.聞きたくもない話かもしれないが,情報処理演習の成績評価が「A+」になるか「A」になるか,はたまた「?」か「?」か,よもや「?」には・・・などという極限状態においても,この「データ並べ替え」は本領発揮している.