STORY #3
Extracting valuable information from big data to design human to human/computer interactions

Yoko Nishihara
Associate Professor,
College of Information
Science and Engineering
Learning Japanese using manga recommended by a new intelligent software
The world is overflowing with information. But if one is unable to pick out the important information from the pile, all the information is of no value. With improvements in the information processing capabilities of computers, big data can be processed and analyzed. Consequently, there is greater potential to utilize information. Thus, by analyzing big data, it has become possible to identify useful information that no one had noticed before.
Yoko Nishihara has conducted research on information extraction technology, such as text mining technology. Information extraction technology has expanded the range of ways in which information can be used. Text mining is a linguistic analysis processing method that finds the characteristic features of text data. A result of Nishihara’s research using text mining was a Japanese language learning tool for non-Japanese people, that uses manga and anime as its media.
Describing how the idea came to her, Nishihara says, “When I found out that many international students in my laboratory used Japanese manga and anime to learn Japanese, I thought perhaps these materials could be standardized in language education.” Manga has many genres, ranging from shōjo manga (which are aimed at teenage girls) to action (aimed at teenage boys), fantasy, and career-related manga (which have an adult protagonist). Anyone from any walk of life can find a type of manga that suits their Japanese language educational needs. For example, an international employee at a corporation can learn from career-oriented manga and pick up on Japanese that would be useful in their daily life. Therefore, Nishihara and her student developed a system that could automatically select the appropriate manga for a learner of Japanese based on their gender, age, occupation, etc.
Nishihara and her student first extracted texts from many manga in a dataset called “Manga109.” This dataset is publicly available for academic research. Using language processing software, they divided all the text in the manga into individual words and measured the level of difficulty of each word according to the Japanese Language Proficiency Test. They then applied the sum of the score to assessing the difficulty levels of the manga themselves. When the learning level of a user is fed into this system, manga appropriate for their current abilities to understand and use the Japanese language is suggested.
To evaluate the effectiveness of their system, Nishihara and her student conducted a field experiment for university students in China who were studying Japanese. “When we compared the results of the Japanese Proficiency Test between the group who studied Japanese using the manga recommended by the system and the group who used randomly assigned manga, we found that the former showed greater improvement in their scores.”
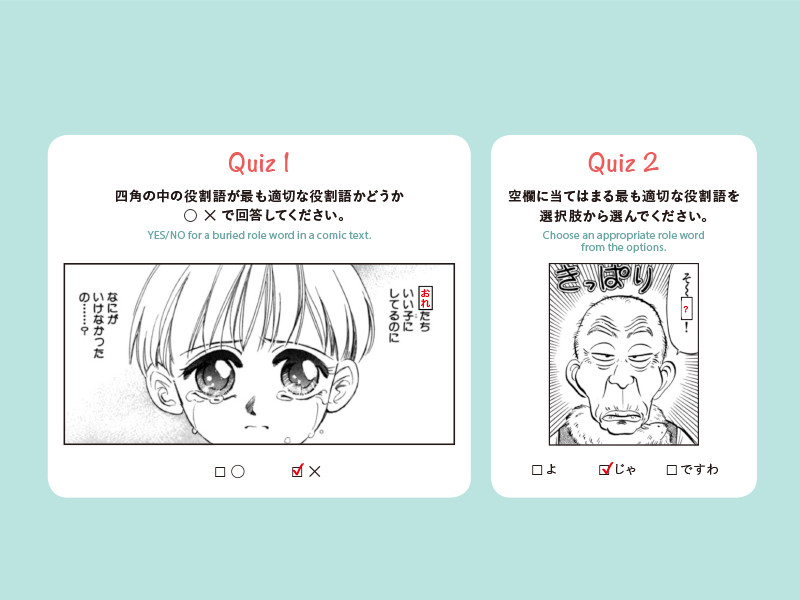
The Japanese language learning tool also assists the user in learning the role words (also known as stereotypical speech) of Japanese. A barrier international learners face in their Japanese learning journey is that there is a different word for each role an individual can assume. For instance, the English word “you” can translate to various words in Japanese based on the context and attributes of the speaker: あなた (anata), あんた (anta), お前 (omae), 君 (kimi), 貴様 (kisama), etc. The tool allows the user to enter such role words into it so that it may find frames from manga that use them. For example, seeing the word お前 (omae) used in context in a scene in a manga will allow the learner to understand its proper use clearly. This tool is available for free on the Web.
Once again, they evaluated the effectiveness of the tool with a field experiment considering two groups of youth in their 20’s: those studying Japanese in Canada and Chinese youth learning the language in Japan. Results showed that the group using the tool to learn role words did better than the group who studied from textbooks.

Source: “Platinum Jungle” ©Masami Shinohara, from Manga109 / Source: “Heisei Jimen” ©Koichi Yamada, from Manga109
They have also been exploring ways to design new interactions using information extraction technology. One of the outcomes of their research is a touch panel interface that records patients’ pain. They developed the interface in collaboration with a physical therapist at a hospital. “One of the challenges physical therapists face is that they are unable to get an accurate description of their patients’ conditions from their patients. This makes it difficult for them to provide effective treatment to their patients,” Nishihara explains.
Often, several patients are unable to express their pain in appropriate terms or unable to describe the severity or progression of their pain. To assist therapists in such situations, Nishihara and her team came up with an idea for an interface into which they fed a list of approximately 20 different pain expressions, such as pounding, or like being pricked by a needle. Patients select terms most closely representing their symptoms so their therapists would have a greater grasp of the kind of pain they’re experiencing. The interface not only assists patients with pinpointing their pain type and level, but also allows them to show the location and degree of pain. With this interface, the accuracy of patient-therapist interaction can be increased and the time taken for these interactions also can be decreased.
This interface might be quite effective for children or international patients who are limited in their vocabulary. “The expressions of pain on the interface are taken from the McGill Pain Questionnaire, which is used globally and can be easily made available in multiple languages. At a time when the number of international visitors to Japan is increasing, this interface could be quite useful for treating international patients in Japanese hospitals. We strongly hope this interface will be adopted by the medical field.”
With this hope in mind Nishihara advances her research, finding solution to how one can extract useful information from the great pile of information that society generates?


- Yoko Nishihara
- Associate Professor, College of Information Science and Engineering
- Research Themes: Analysis and design interactions, and supporting creative activities
- Specialties: Human interface and interaction, intelligence informatics, web informatics, service informatics, library informatics, humanities and social informatics