音声は、周りの世界を認知したり、コミュニケーションを取る上で極めて重要な手段である。話している言葉を理解する、話し声から性別や年齢、喜怒哀楽などの感情を推定する、あるいは音の大きさや聴こえてきた方向から人の位置や音の発生源を突き止めるなど、音声認識に関わる技術は近年、目覚ましい勢いで進化している。
福森隆寛も音声・環境音認識において新領域を開拓しようとしている研究者の一人だ。福森が挑むのは、音声から「危機」を検知すること。危機的状況を示す要素の一つとして「叫び声」に着目し、人の叫び声を認知して危機か否かを自動で検知する「ロボット聴覚」の開発を目指している。最近の研究で、ディープラーニングを用いて平静時の音声と危機を知らせる悲鳴とを聞き分けるシステムの開発に成功した。
「一般的な音声認識と異なり、『叫び声』から危機的な状況を判断するのが難しいのは、危機がどこでどのような状況で起こるかわからないからです。雑多な音であふれ返った騒々しい場所や、マイクロフォンから離れた場所で声が発せられることも考慮に入れ、叫び声を高精度に検知する方策を考える必要があります」と福森は明かす。
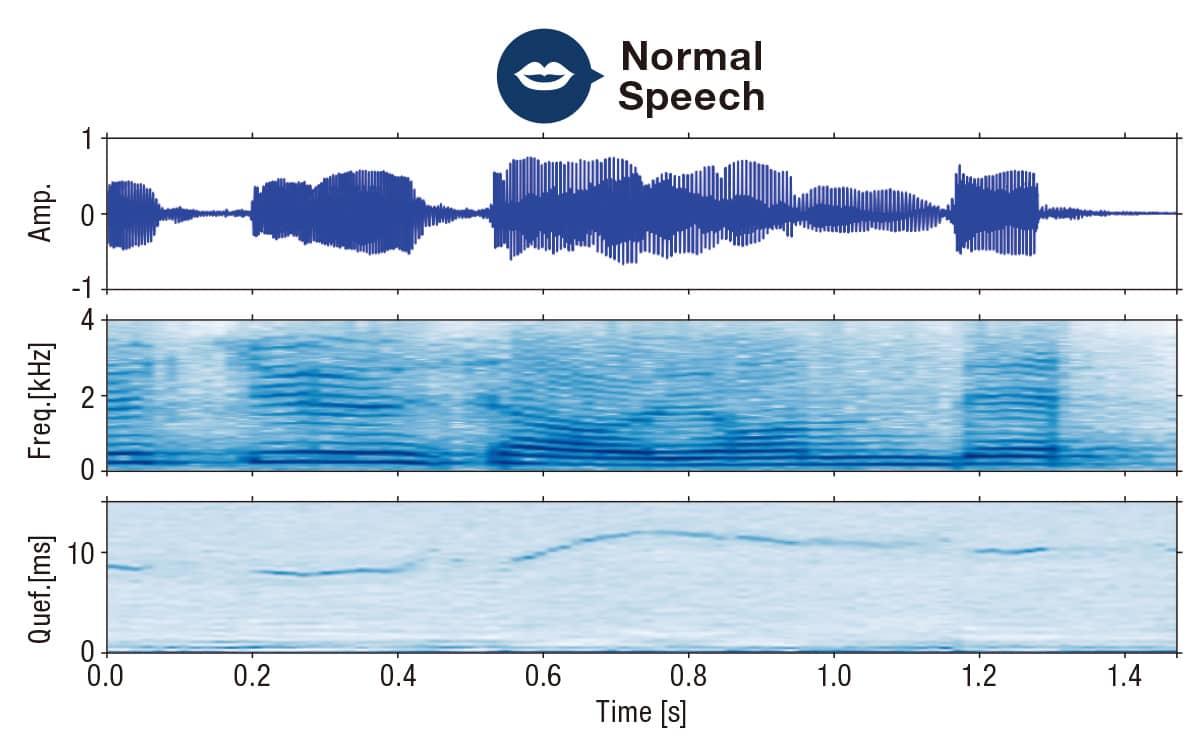
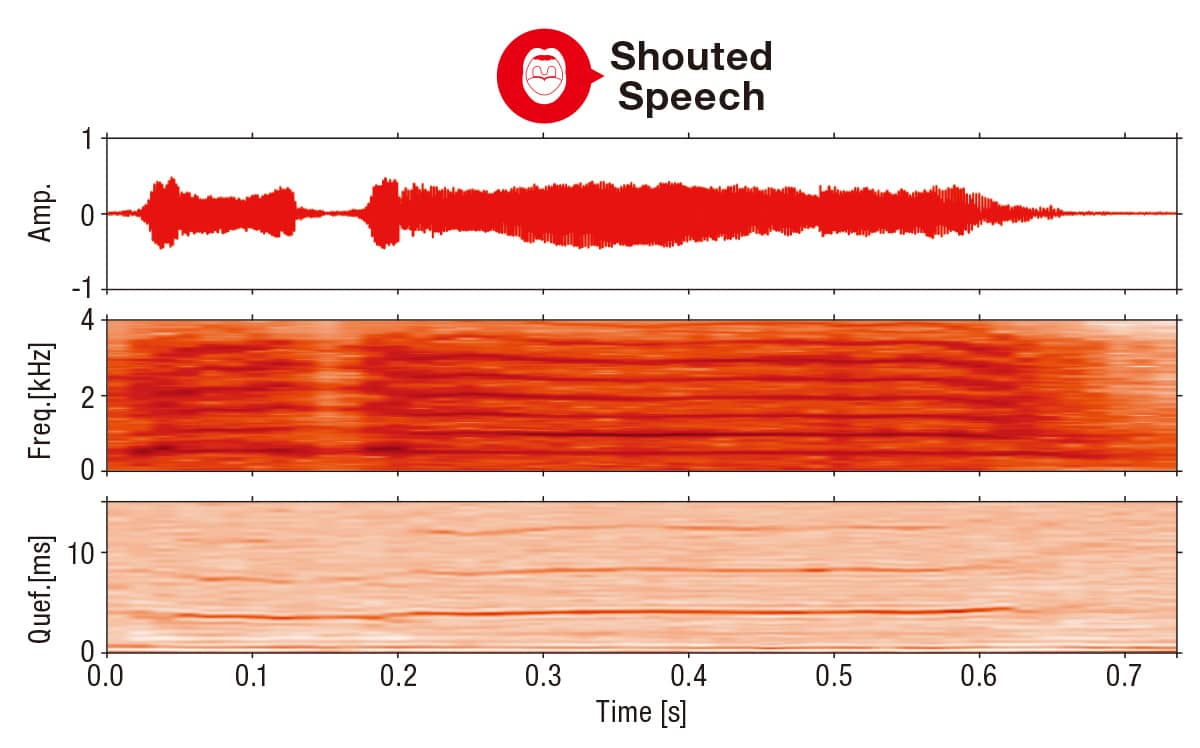
福森によると、従来の音声認識では多くの場合、MFCC(メル周波数ケプストラム係数)から認識に重要な特徴量を導き出す方法が用いられる。人は喉元の声帯を振動させ、音波を喉・口などの声道を通過させることによってさまざまな音声を生成する。MFCCは声道に関する特徴をケプストラム領域で表現するように設計されたもの。人の聴覚特性に合わせ、高周波帯域は粗く、低周波帯域を細かくサンプリングするのが特徴だ。「しかし平静時の音声と叫び声では、声帯と声道の動きが大きく異なることがわかってきました」と福森。それによると、人が叫ぶ時は声帯やその付近の発声器官が強く振動したり、語尾の接続時間が平静発話よりも長くなる傾向がある。そのためMFCCだけでは悲鳴の特徴を十分に捉えることができないのだ。
解決策を検討していた福森は、先行研究から悲鳴の高調波成分のエネルギーが平静音声よりも強いことに注目。悲鳴を検知するには、音声のスペクトル(周波数)領域の特徴を捉えることも有効だと気づき、スペクトル領域とケプストラム領域の両方の特徴量を使用することで検知の精度を高めようと考えた。
まず男女の平静の音声と危機的状況を想起させる叫び声を収録し、合計で約1,000サンプルを収集。それぞれの音声からスペクトログラムとケプストログラム両方の特徴量を抽出してディープラーニングで学習させ、平静音声と悲鳴を分類するモデルを構築した。
「このモデルを用いて評価実験を行った結果、平均でおよそ94.1%、極めて騒々しい環境でも80%もの高い確率で叫び声を検知できることを確かめました」と福森。従来のMFCCを使用する方法よりも高精度に叫び声を判別でき、しかも雑音の多い環境ほどその強みを発揮できることを実証した。
「AI技術の浸透によって音声認識技術の進化が目覚ましい一方で、危機を検知するロボット聴覚の技術開発はやや遅れを取っていました」と福森。その理由の一つとして、ディープラーニングに必要な音声サンプルを収集する難しさを挙げる。福森の研究が成功した一因には、質の高いサンプルを粘り強く収集したところにもあったのだ。
さらに現在、発せられた音声がどの程度「叫び声らしい」のか、叫び声の強度を推計するシステムの開発にも着手している。まず音声サンプルのさらなる充実を図るとともに、「叫び声の強度」の定量化を試みている。叫び声を複数人に聞かせ、どの程度「叫び声らしい」のかを点数で評価してもらい、そのデータをもとにディープラーニングを用いて推定モデルを構築するという。
「叫び声の強度に加えて、叫び声が本当に危機的状況を訴えているものか、あるいは歓声や笑い声のようなポジティブな音声なのかを判定するシステムの開発も目指しています」と福森。将来は、スマートフォンに搭載し、日常生活の防犯などに生かせる「危機検知アプリ」の開発につなげたいと展望する。
現在犯罪・事故の検知には、動画・画像情報を利用する防犯カメラなどが普及している。その後を追うように、近年はマイクロフォンを使って「音」から異常事態を検知する「音響監視システム」が注目されつつあるという。「ロボット聴覚は、動画・画像情報の弱点を補い、監視や危険察知能力を高める上で非常に有効です」と可能性を語った福森。「危機的状況を検知できる聴力を持ったロボットが凶悪事件や大事故をいち早く察知し、国民を守る。そんな時代の到来に貢献したい」。福森の研究はまだまだ発展していく。